这是我的学习笔记,所有的代码来自序 - Hello 算法和Navigation的算法笔记,放在这里仅供我自己总结学习和记录
链表
链表的简单介绍
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| struct ListNode {
int val;
struct ListNode *next;
};
// 输入一个数组,转换为一条单链表
struct ListNode* createLinkedList(int* arr, int arrSize) {
if (arr == NULL || arrSize == 0) {
return NULL;
}
struct ListNode* head = (struct ListNode*)malloc(sizeof(struct ListNode));
head->val = arr[0];
head->next = NULL;
struct ListNode* cur = head;
for (int i = 1; i < arrSize; i++) {
cur->next = (struct ListNode*)malloc(sizeof(struct ListNode));
cur->next->val = arr[i];
cur->next->next = NULL;
cur = cur->next;
}
return head;
}
|
直接附上这段将一个数组转化为链表的代码
最上面的
1
2
3
4
| struct ListNode {
int val;
struct ListNode *next;
};
|
是定义链表,每一个链表的内部都由两个部分,一个是存储的数据,另一个就是指向下一个内存的指针
下面是一个将数组转化为链表的一串代码
1
| struct ListNode* createLinkedList(int* arr, int arrSize)
|
这是定义了一个返回类型为 struct ListNode* 的函数,为什么是这个函数呢,考虑到我们将一个数组转化为链表后,必须有一个指针指向第一个元素的位置,要不就找不到这块内存了,而函数内部的变量是有作用范围的,所以最后会返回一个 head指针,它的类型是 struct ListNode*
1
2
3
4
| struct ListNode* createLinkedList(int* arr, int arrSize) {
if (arr == NULL || arrSize == 0) {
return NULL;
}
|
确保安全吧,毕竟要是没有这个数组,指针不能乱指位置,用NULL是为了安全
1
2
3
4
5
6
7
8
9
10
11
| struct ListNode* head = (struct ListNode*)malloc(sizeof(struct ListNode));
head->val = arr[0];
head->next = NULL;
struct ListNode* cur = head;
for (int i = 1; i < arrSize; i++) {
cur->next = (struct ListNode*)malloc(sizeof(struct ListNode));
cur->next->val = arr[i];
cur->next->next = NULL;
cur = cur->next;
}
return head;
|
好了,现在开始是重头戏了
首先我们先定义了一个结构体指针,也就是指向第一个数据的指针,并给这个指针分配了内存
然后将值赋给内存,并将为了防止野指针,使用NULL
cur就是在函数中使用的是个中间变量,毕竟我们对下一个节点赋值的话不能使用已有的指针(这里已有的指针是指指向下一个节点的指针)
这是一个常规的赋值,然后就是使用for循环来简化赋值过程
用cur来访问当循环的节点内的指针
第一步肯定是将NULL的指针改为指向一个内存的指针,之后就是赋值,用NULL保证指针的安全,将cur这个暂时使用的指针指向下一个位置
补充另一个链表初始化的一些写法
1
2
3
4
5
| /* 链表节点结构体 */
typedef struct ListNode {
int val; // 节点值
struct ListNode *next; // 指向下一节点的指针
} ListNode;
|
typedef是定义一个变量名字,相当于ListNode已经可以用它来定义struct ListNode类型的变量了,在后面定义的时候可以省略关键字
例如
1
2
3
4
5
6
7
8
| /* 构造函数 */
ListNode *newListNode(int val) {
ListNode *node;
node = (ListNode *) malloc(sizeof(ListNode));
node->val = val;
node->next = NULL;
return node;
}
|
注意这里的链表没有链化,也就是说没有指向下一个地址
链表常用操作
初始化链表
这是上面哪个例的延续
1
2
3
4
5
6
7
8
9
10
11
12
| /* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
ListNode* n0 = newListNode(1);
ListNode* n1 = newListNode(3);
ListNode* n2 = newListNode(2);
ListNode* n3 = newListNode(5);
ListNode* n4 = newListNode(4);
// 构建节点之间的引用
n0->next = n1;
n1->next = n2;
n2->next = n3;
n3->next = n4;
|
应该没什么说的,我觉得挺好懂的
插入节点
1
2
3
4
5
6
| /* 在链表的节点 n0 之后插入节点 P */
void insert(ListNode *n0, ListNode *P) {
ListNode *n1 = n0->next;
P->next = n1;
n0->next = P;
}
|
由于是函数,所以第一步是将n1定义出来
P->next = n1;是将P指向对应的位置
n0->next = P;将n0指向P
就成功插入了,时间复杂度是1
删除节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /* 删除链表的节点 n0 之后的首个节点 */
// 注意:stdio.h 占用了 remove 关键词
void removeItem(ListNode *n0) {
if (!n0->next)
return;
// 指针为NULL(假)
// !NULL → !0 → 1(真)
// 所以条件成立,执行return
// n0 -> P -> n1
ListNode *P = n0->next;// 步骤1:保存要删除的节点P的地址
ListNode *n1 = P->next;// 步骤2:保存P的下一个节点n1的地址
n0->next = n1;// 步骤3:跳过P,直接连接n0和n1
// 释放内存
free(P);
}
|
访问节点
1
2
3
4
5
6
7
8
9
| /* 访问链表中索引为 index 的节点 */
ListNode *access(ListNode *head, int index) {
for (int i = 0; i < index; i++) {
if (head == NULL)
return NULL;
head = head->next;
}
return head;
}
|
查找节点
1
2
3
4
5
6
7
8
9
10
11
| /* 在链表中查找值为 target 的首个节点 */
int find(ListNode *head, int target) {
int index = 0;
while (head) {
if (head->val == target)
return index;
head = head->next;
index++;
}
return -1;
}
|
双向链表
创建双向链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| struct DoublyListNode {
int val;
struct DoublyListNode *next, *prev;
};
struct DoublyListNode* createDoublyLinkedList(int* arr, int arrSize) {
if (arr == NULL || arrSize == 0) {
return NULL;
}
struct DoublyListNode* head = (struct DoublyListNode*)malloc(sizeof(struct DoublyListNode));
head->val = arr[0];
head->next = NULL;
head->prev = NULL;
struct DoublyListNode* cur = head;
// for 循环迭代创建双链表
for (int i = 1; i < arrSize; i++) {
struct DoublyListNode* newNode = (struct DoublyListNode*)malloc(sizeof(struct DoublyListNode));
newNode->val = arr[i];
newNode->next = NULL;
cur->next = newNode;
newNode->prev = cur;
cur = cur->next;
}
return head;
}
|
查和改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| // 创建一条双链表
int arr[] = {1, 2, 3, 4, 5};
struct DoublyListNode* head = createDoublyLinkedList(arr, 5);
struct DoublyListNode* tail = NULL;
// 从头节点向后遍历双链表
for (struct DoublyListNode* p = head; p != NULL; p = p->next) {
printf("%d\n", p->val);
tail = p;
}
// 从尾节点向前遍历双链表
for (struct DoublyListNode* p = tail; p != NULL; p = p->prev) {
printf("%d\n", p->val);
}
|
增
在双链表的头部增加元素(这个操作的时间复杂度是1)
1
2
3
4
5
6
7
8
9
10
11
12
| // 创建一条双链表
int arr[] = {1, 2, 3, 4, 5};
struct DoublyListNode* head = createDoublyLinkedList(arr, 5);
// 在双链表头部插入新节点 0
struct DoublyListNode* newHead = (struct DoublyListNode*)malloc(sizeof(struct DoublyListNode));
newHead->val = 0;
newHead->prev = NULL;
newHead->next = head;
head->prev = newHead;
head = newHead;
// 现在链表变成了 0 -> 1 -> 2 -> 3 -> 4 -> 5
|
在双链表的尾部增加元素(看情况,如果有尾链表,那操作的时间复杂度是1,如果没有的话,由于需要遍历,所以时间复杂度是n)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // 创建一条双链表
int arr[] = {1, 2, 3, 4, 5};
struct DoublyListNode* head = createDoublyLinkedList(arr, 5);
struct DoublyListNode* tail = head;
// 先走到链表的最后一个节点
while (tail->next != NULL) {
tail = tail->next;
}
// 在双链表尾部插入新节点 6
struct DoublyListNode* newNode = (struct DoublyListNode*)malloc(sizeof(struct DoublyListNode));
newNode->val = 6;
newNode->next = NULL;
tail->next = newNode;
newNode->prev = tail;
// 更新尾节点引用
tail = newNode;
// 现在链表变成了 1 -> 2 -> 3 -> 4 -> 5 -> 6
|
在中间插入新元素(时间复杂度是n)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| // 创建一条双链表
int arr[] = {1, 2, 3, 4, 5};
struct DoublyListNode* head = createDoublyLinkedList(arr, 5);
// 想要插入到索引 3(第 4 个节点)
// 需要操作索引 2(第 3 个节点)的指针
struct DoublyListNode* p = head;
for (int i = 0; i < 2; i++) {
p = p->next;
}
// 组装新节点
struct DoublyListNode* newNode = (struct DoublyListNode*)malloc(sizeof(struct DoublyListNode));
newNode->val = 66;
newNode->next = p->next;
newNode->prev = p;
// 插入新节点
p->next->prev = newNode;
p->next = newNode;
// 现在链表变成了 1 -> 2 -> 3 -> 66 -> 4 -> 5
|
删
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| // 创建一条双链表
int arr[] = {1, 2, 3, 4, 5};
struct DoublyListNode* head = createDoublyLinkedList(arr, 5);
// 删除第 4 个节点
// 先找到第 3 个节点
struct DoublyListNode* p = head;
for (int i = 0; i < 2; i++) {
p = p->next;
}
// 现在 p 指向第 3 个节点,我们它后面那个节点摘除出去
struct DoublyListNode* toDelete = p->next;
// 把 toDelete 从链表中摘除
p->next = toDelete->next;
toDelete->next->prev = p;
// 把 toDelete 的前后指针都置为 null 是个好习惯(可选)
toDelete->next = NULL;
toDelete->prev = NULL;
free(toDelete);//毕竟删除,最好还是要释放内存的
// 现在链表变成了 1 -> 2 -> 3 -> 5
|
头部和尾部删除代码类似,这里就不赘述了
栈
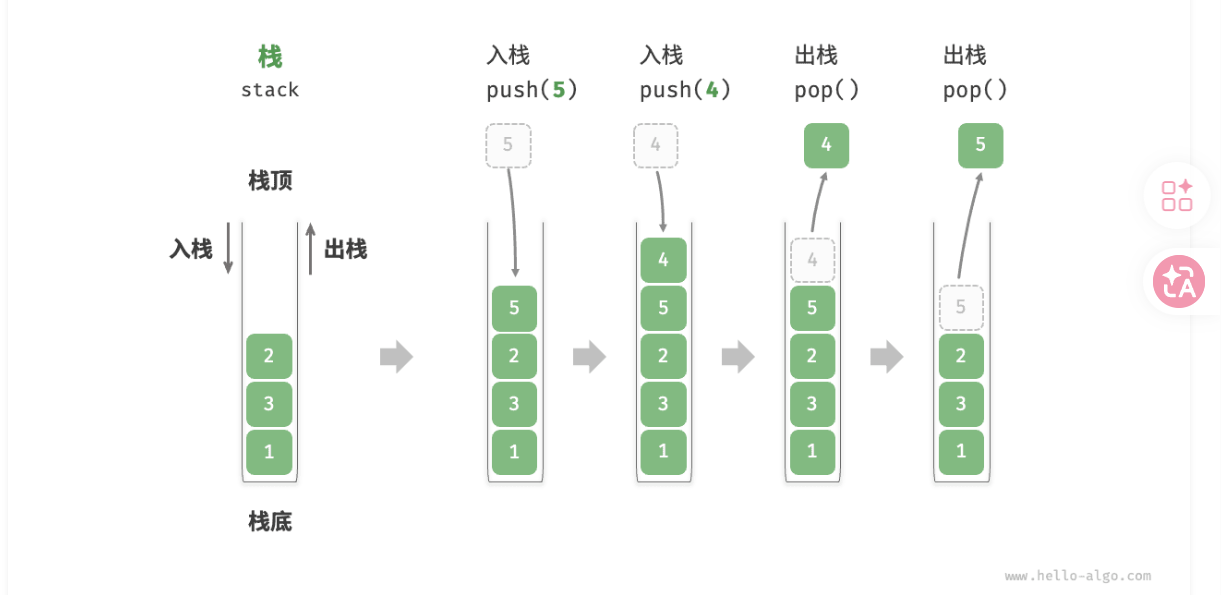
栈(stack)是一种遵循先入后出逻辑的线性数据结构。
我们可以将栈类比为桌面上的一摞盘子,规定每次只能移动一个盘子,那么想取出底部的盘子,则需要先将上面的盘子依次移走。我们将盘子替换为各种类型的元素(如整数、字符、对象等),就得到了栈这种数据结构。
我们把堆叠元素的顶部称为“栈顶”,底部称为“栈底”。将把元素添加到栈顶的操作叫作“入栈”,删除栈顶元素的操作叫作“出栈”。
基于链表实现的栈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| //补充的链表的定义,原来并没有,但这也是需要的,要不代码有一点不完整
typedef struct ListNode {
int val;
struct ListNode *next;
} ListNode;
/* 基于链表实现的栈 */
typedef struct {
ListNode *top; // 将头节点作为栈顶
int size; // 栈的长度
} LinkedListStack;
/* 构造函数 */
LinkedListStack *newLinkedListStack() {
LinkedListStack *s = malloc(sizeof(LinkedListStack));
s->top = NULL;
s->size = 0;
return s;
}
/* 析构函数 */
void delLinkedListStack(LinkedListStack *s) {
while (s->top) {
ListNode *n = s->top->next;
free(s->top);
s->top = n;
}
free(s);//别忘了释放这里临时使用指针的内存
}
//就是在删除栈,每一步都是删除栈顶的元素,再将下一个改为栈顶
/* 获取栈的长度 */
int size(LinkedListStack *s) {
return s->size;
}
/* 判断栈是否为空 */
bool isEmpty(LinkedListStack *s) {
return size(s) == 0;
}
/* 入栈 */
void push(LinkedListStack *s, int num) {
ListNode *node = (ListNode *)malloc(sizeof(ListNode));
node->next = s->top; // 更新新加节点指针域
node->val = num; // 更新新加节点数据域
s->top = node; // 更新栈顶
s->size++; // 更新栈大小
}
/* 访问栈顶元素 */
int peek(LinkedListStack *s) {
if (s->size == 0) {
printf("栈为空\n");
return INT_MAX; //int类型的最大数,只要发现是这个数,就说明栈为空
}
return s->top->val;
}
/* 出栈 */
int pop(LinkedListStack *s) {
int val = peek(s);
ListNode *tmp = s->top;
s->top = s->top->next;
// 释放内存
free(tmp);
s->size--;
return val;
}
|
基于数组实现的栈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| /* 基于数组实现的栈 */
typedef struct {
int *data;//为了方便扩容,所以这里使用的是指针,但下文并没有写扩容函数
int size;
} ArrayStack;
/* 构造函数 */
ArrayStack *newArrayStack() {
ArrayStack *stack = malloc(sizeof(ArrayStack));
// 初始化一个大容量,避免扩容
stack->data = malloc(sizeof(int) * MAX_SIZE);
stack->size = 0;
return stack;
}
/* 析构函数 */
void delArrayStack(ArrayStack *stack) {
free(stack->data);
free(stack);//不能忘记释放这里的内存
}
/* 获取栈的长度 */
int size(ArrayStack *stack) {
return stack->size;
}
/* 判断栈是否为空 */
bool isEmpty(ArrayStack *stack) {
return stack->size == 0;
}
/* 入栈 */
void push(ArrayStack *stack, int num) {
if (stack->size == MAX_SIZE) {
printf("栈已满\n");
return;
}
stack->data[stack->size] = num;//C语言中指针和数组的访问方式相同
stack->size++;
}
/* 访问栈顶元素 */
int peek(ArrayStack *stack) {
if (stack->size == 0) {
printf("栈为空\n");
return INT_MAX;
}
return stack->data[stack->size - 1];//注意这里的减1
}
/* 出栈 */
int pop(ArrayStack *stack) {
int val = peek(stack);
stack->size--;
return val;
}
|
支持操作
两种实现都支持栈定义中的各项操作。数组实现额外支持随机访问,但这已超出了栈的定义范畴,因此一般不会用到。
时间效率
在基于数组的实现中,入栈和出栈操作都在预先分配好的连续内存中进行,具有很好的缓存本地性,因此效率较高。然而,如果入栈时超出数组容量,会触发扩容机制,导致该次入栈操作的时间复杂度变为n
在基于链表的实现中,链表的扩容非常灵活,不存在上述数组扩容时效率降低的问题。但是,入栈操作需要初始化节点对象并修改指针,因此效率相对较低。不过,如果入栈元素本身就是节点对象,那么可以省去初始化步骤,从而提高效率。
队列
用链表实现的队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
| //同样补充链表的定义
typedef struct ListNode {
int val;
struct ListNode *next;
} ListNode;
/* 基于链表实现的队列 */
typedef struct {
ListNode *front, *rear;
int queSize;
} LinkedListQueue;
/* 构造函数 */
LinkedListQueue *newLinkedListQueue() {
LinkedListQueue *queue = (LinkedListQueue *)malloc(sizeof(LinkedListQueue));
queue->front = NULL;
queue->rear = NULL;
queue->queSize = 0;
return queue;
}
/* 析构函数 */
void delLinkedListQueue(LinkedListQueue *queue) {
// 释放所有节点
while (queue->front != NULL) {
ListNode *tmp = queue->front;
queue->front = queue->front->next;
free(tmp);
}
// 释放 queue 结构体
free(queue);//再提醒一下自己,不能把这个忘了
}
/* 获取队列的长度 */
int size(LinkedListQueue *queue) {
return queue->queSize;
}
/* 判断队列是否为空 */
bool empty(LinkedListQueue *queue) {
return (size(queue) == 0);
}
/* 入队 */
void push(LinkedListQueue *queue, int num) {
// 尾节点处添加 node
ListNode *node = newListNode(num);
// 如果队列为空,则令头、尾节点都指向该节点
if (queue->front == NULL) {
queue->front = node;
queue->rear = node;
}
// 如果队列不为空,则将该节点添加到尾节点后
else {
queue->rear->next = node;
queue->rear = node;
}
queue->queSize++;
}
/*
front rear
↓ ↓
[1] -> [2] -> [3] -> NULL
↑
node
*/
/* 访问队首元素 */
int peek(LinkedListQueue *queue) {
assert(size(queue) && queue->front);
/*这是一个宏,如果条件为真,什么都不做,如果条件为假,程序会终止并输出错误信息 */
return queue->front->val;
}
/* 出队 */
int pop(LinkedListQueue *queue) {
int num = peek(queue);
ListNode *tmp = queue->front;
queue->front = queue->front->next;
free(tmp);
queue->queSize--;
return num;
}
/* 打印队列 */
void printLinkedListQueue(LinkedListQueue *queue) {
int *arr = malloc(sizeof(int) * queue->queSize);
// 拷贝链表中的数据到数组
int i;
ListNode *node;
for (i = 0, node = queue->front; i < queue->queSize; i++) {
arr[i] = node->val;
node = node->next;
}
printArray(arr, queue->queSize);
free(arr);
}
|
基于数组实现的队列
在数组中删除首元素的时间复杂度为n,这会导致出队操作效率较低。然而,我们可以采用以下巧妙方法来避免这个问题。
我们可以使用一个变量 front 指向队首元素的索引,并维护一个变量 size 用于记录队列长度。定义 rear = front + size ,这个公式计算出的 rear 指向队尾元素之后的下一个位置。
基于此设计,数组中包含元素的有效区间为 [front, rear - 1]
- 入队操作:将输入元素赋值给
rear 索引处,并将 size 增加 1 。 - 出队操作:只需将
front 增加 1 ,并将 size 减少 1 。
你可能会发现一个问题:在不断进行入队和出队的过程中,front 和 rear 都在向右移动,当它们到达数组尾部时就无法继续移动了。为了解决此问题,我们可以将数组视为首尾相接的“环形数组”。
对于环形数组,我们需要让 front 或 rear 在越过数组尾部时,直接回到数组头部继续遍历。这种周期性规律可以通过“取余操作”来实现,代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| /* 基于环形数组实现的队列 */
typedef struct {
int *nums; // 用于存储队列元素的数组
int front; // 队首指针,指向队首元素
int queSize; // 当前队列的元素数量
int queCapacity; // 队列容量
} ArrayQueue;
/* 构造函数 */
ArrayQueue *newArrayQueue(int capacity) {
ArrayQueue *queue = (ArrayQueue *)malloc(sizeof(ArrayQueue));
// 初始化数组
queue->queCapacity = capacity;
queue->nums = (int *)malloc(sizeof(int) * queue->queCapacity);
queue->front = queue->queSize = 0;
return queue;
}
/* 析构函数 */
void delArrayQueue(ArrayQueue *queue) {
free(queue->nums);
free(queue);
}
/* 获取队列的容量 */
int capacity(ArrayQueue *queue) {
return queue->queCapacity;
}
/* 获取队列的长度 */
int size(ArrayQueue *queue) {
return queue->queSize;
}
/* 判断队列是否为空 */
bool empty(ArrayQueue *queue) {
return queue->queSize == 0;
}
/* 访问队首元素 */
int peek(ArrayQueue *queue) {
assert(size(queue) != 0);
return queue->nums[queue->front];
}
/* 入队 */
void push(ArrayQueue *queue, int num) {
if (size(queue) == capacity(queue)) {
printf("队列已满\r\n");
return;
}
// 计算队尾指针,指向队尾索引 + 1
// 通过取余操作实现 rear 越过数组尾部后回到头部
int rear = (queue->front + queue->queSize) % queue->queCapacity;
// 将 num 添加至队尾
queue->nums[rear] = num;
queue->queSize++;
}
/* 出队 */
int pop(ArrayQueue *queue) {
int num = peek(queue);
// 队首指针向后移动一位,若越过尾部,则返回到数组头部
queue->front = (queue->front + 1) % queue->queCapacity;
queue->queSize--;
return num;
}
/* 返回数组用于打印 */
int *toArray(ArrayQueue *queue, int *queSize) {
*queSize = queue->queSize;
int *res = (int *)calloc(queue->queSize, sizeof(int));
//calloc就是专门为分配数组设计的,分配内存后自动填充为0
int j = queue->front;
//设计这个循环就是把一个环形数组再转化为正常的数组
for (int i = 0; i < queue->queSize; i++) {
res[i] = queue->nums[j % queue->queCapacity];
j++;
}
return res;
}
|
这里的取余操作其实是通过数组的整体的数量来控制首指针和尾指针的位置,只要刚好到达数组的数量,那取余操作就可以将他变为0,其实就是商1取0
以上实现的队列仍然具有局限性:其长度不可变。然而,这个问题不难解决,我们可以将数组替换为动态数组,从而引入扩容机制。
两种实现的对比结论与栈一致,在此不再赘述。
双向队列
双向队列(double-ended queue)提供了更高的灵活性,允许在头部和尾部执行元素的添加或删除操作。
基于双向链表实现的双向队列
对于双向队列而言,头部和尾部都可以执行入队和出队操作。换句话说,双向队列需要实现另一个对称方向的操作。为此,我们采用“双向链表”作为双向队列的底层数据结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
| /* 双向链表节点 */
typedef struct DoublyListNode {
int val; // 节点值
struct DoublyListNode *next; // 后继节点
struct DoublyListNode *prev; // 前驱节点
} DoublyListNode;
/* 构造函数 */
DoublyListNode *newDoublyListNode(int num) {
DoublyListNode *new = (DoublyListNode *)malloc(sizeof(DoublyListNode));
new->val = num;
new->next = NULL;
new->prev = NULL;
return new;
}
/* 析构函数 */
void delDoublyListNode(DoublyListNode *node) {
free(node);
}
/* 基于双向链表实现的双向队列 */
typedef struct {
DoublyListNode *front, *rear; // 头节点 front ,尾节点 rear
int queSize; // 双向队列的长度
} LinkedListDeque;
/* 构造函数 */
LinkedListDeque *newLinkedListDeque() {
LinkedListDeque *deque = (LinkedListDeque *)malloc(sizeof(LinkedListDeque));
deque->front = NULL;
deque->rear = NULL;
deque->queSize = 0;
return deque;
}
/* 析构函数 */
void delLinkedListdeque(LinkedListDeque *deque) {
// 释放所有节点
for (int i = 0; i < deque->queSize && deque->front != NULL; i++) {
DoublyListNode *tmp = deque->front;
deque->front = deque->front->next;
free(tmp);
}
// 释放 deque 结构体
free(deque);
}
/* 获取队列的长度 */
int size(LinkedListDeque *deque) {
return deque->queSize;
}
/* 判断队列是否为空 */
bool empty(LinkedListDeque *deque) {
return (size(deque) == 0);
}
/* 入队 */
void push(LinkedListDeque *deque, int num, bool isFront) {
DoublyListNode *node = newDoublyListNode(num);
// 若链表为空,则令 front 和 rear 都指向node
if (empty(deque)) {
deque->front = deque->rear = node;
}
// 队首入队操作
else if (isFront) {
// 将 node 添加至链表头部
deque->front->prev = node;
node->next = deque->front;
deque->front = node; // 更新头节点
}
// 队尾入队操作
else {
// 将 node 添加至链表尾部
deque->rear->next = node;
node->prev = deque->rear;
deque->rear = node;
}
deque->queSize++; // 更新队列长度
}
/* 队首入队 */
void pushFirst(LinkedListDeque *deque, int num) {
push(deque, num, true);
}
/* 队尾入队 */
void pushLast(LinkedListDeque *deque, int num) {
push(deque, num, false);
}
/* 访问队首元素 */
int peekFirst(LinkedListDeque *deque) {
assert(size(deque) && deque->front);
return deque->front->val;
}
/* 访问队尾元素 */
int peekLast(LinkedListDeque *deque) {
assert(size(deque) && deque->rear);
return deque->rear->val;
}
//这里的访问都用到了assert函数,为了是访问的安全
/* 出队 */
int pop(LinkedListDeque *deque, bool isFront) {
if (empty(deque))
return -1;
int val;
// 队首出队操作
if (isFront) {
val = peekFirst(deque); // 暂存头节点值
DoublyListNode *fNext = deque->front->next;
if (fNext) {
fNext->prev = NULL;
deque->front->next = NULL;
}
delDoublyListNode(deque->front);
deque->front = fNext; // 更新头节点
}
// 队尾出队操作
else {
val = peekLast(deque); // 暂存尾节点值
DoublyListNode *rPrev = deque->rear->prev;
if (rPrev) {
rPrev->next = NULL;
deque->rear->prev = NULL;
}
delDoublyListNode(deque->rear);
deque->rear = rPrev; // 更新尾节点
}
deque->queSize--; // 更新队列长度
return val;
}
/* 队首出队 */
int popFirst(LinkedListDeque *deque) {
return pop(deque, true);
}
/* 队尾出队 */
int popLast(LinkedListDeque *deque) {
return pop(deque, false);
}
/* 打印队列 */
void printLinkedListDeque(LinkedListDeque *deque) {
int *arr = malloc(sizeof(int) * deque->queSize);
// 拷贝链表中的数据到数组
int i;
DoublyListNode *node;
for (i = 0, node = deque->front; i < deque->queSize; i++) {
arr[i] = node->val;
node = node->next;
}
printArray(arr, deque->queSize);
free(arr);
}
|
用数组实现双向队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
| /* 基于环形数组实现的双向队列 */
typedef struct {
int *nums; // 用于存储队列元素的数组
int front; // 队首指针,指向队首元素
int queSize; // 尾指针,指向队尾 + 1
int queCapacity; // 队列容量
} ArrayDeque;
/* 构造函数 */
ArrayDeque *newArrayDeque(int capacity) {
ArrayDeque *deque = (ArrayDeque *)malloc(sizeof(ArrayDeque));
// 初始化数组
deque->queCapacity = capacity;
deque->nums = (int *)malloc(sizeof(int) * deque->queCapacity);
deque->front = deque->queSize = 0;
return deque;
}
/* 析构函数 */
void delArrayDeque(ArrayDeque *deque) {
// 第1步:先释放数组内存,这里的顺序不能换,因为这个结构体并没有存储数据,数据实则是在nums指向的内存中
free(deque->nums);
free(deque);
}
/* 获取双向队列的容量 */
int capacity(ArrayDeque *deque) {
return deque->queCapacity;
}
/* 获取双向队列的长度 */
int size(ArrayDeque *deque) {
return deque->queSize;
}
/* 判断双向队列是否为空 */
bool empty(ArrayDeque *deque) {
return deque->queSize == 0;
}
/* 计算环形数组索引 */
int dequeIndex(ArrayDeque *deque, int i) {
// 通过取余操作实现数组首尾相连
// 当 i 越过数组尾部时,回到头部
// 当 i 越过数组头部后,回到尾部
return ((i + capacity(deque)) % capacity(deque));
}
/* 队首入队 */
void pushFirst(ArrayDeque *deque, int num) {
if (deque->queSize == capacity(deque)) {
printf("双向队列已满\r\n");
return;
}
// 队首指针向左移动一位
// 通过取余操作实现 front 越过数组头部回到尾部
deque->front = dequeIndex(deque, deque->front - 1);
/*这里其实就想把front向左移动一位,但可能越界,所以就利用了那个函数*/
// 将 num 添加到队首
deque->nums[deque->front] = num;
deque->queSize++;
}
/* 队尾入队 */
void pushLast(ArrayDeque *deque, int num) {
if (deque->queSize == capacity(deque)) {
printf("双向队列已满\r\n");
return;
}
// 计算队尾指针,指向队尾索引 + 1
int rear = dequeIndex(deque, deque->front + deque->queSize);
// 将 num 添加至队尾
deque->nums[rear] = num;
deque->queSize++;
}
/* 访问队首元素 */
int peekFirst(ArrayDeque *deque) {
// 访问异常:双向队列为空
assert(empty(deque) == 0);
return deque->nums[deque->front];
}
/* 访问队尾元素 */
int peekLast(ArrayDeque *deque) {
// 访问异常:双向队列为空
assert(empty(deque) == 0);
int last = dequeIndex(deque, deque->front + deque->queSize - 1);
return deque->nums[last];
}
/* 队首出队 */
int popFirst(ArrayDeque *deque) {
int num = peekFirst(deque);
// 队首指针向后移动一位
deque->front = dequeIndex(deque, deque->front + 1);
deque->queSize--;
return num;
}
/*这里的出队只需要移动指针和将元素个数减少一个就行,不需要移动整个数组,这就是环形数组的好处*/
/* 队尾出队 */
int popLast(ArrayDeque *deque) {
int num = peekLast(deque);
deque->queSize--;
return num;
}
/* 返回数组用于打印 */
int *toArray(ArrayDeque *deque, int *queSize) {
*queSize = deque->queSize;
int *res = (int *)calloc(deque->queSize, sizeof(int));
int j = deque->front;
for (int i = 0; i < deque->queSize; i++) {
res[i] = deque->nums[j % deque->queCapacity];
j++;
}
/*再对这里的取余操作做一个说明吧,j初始化为首元素的下标,j % queCapacity,也是为了保证环形结构*/
return res;
}
|
1
2
3
4
5
6
7
| /* 计算环形数组索引 */
int dequeIndex(ArrayDeque *deque, int i) {
// 通过取余操作实现数组首尾相连
// 当 i 越过数组尾部时,回到头部
// 当 i 越过数组头部后,回到尾部
return ((i + capacity(deque)) % capacity(deque));
}
|
将这部分代码单独拿出来做一个笔记
举个例子,当capacity等于5的时候:
| 情况 | i 例子 | 结果 | 解释 |
|---|
| 正常范围内 | 2 | 2 | 不变 |
| 负数(逆时针) | -1 | 4 | 绕到尾部 |
| 超过容量 | 7 | 2 | 绕回到头部 |
所以函数的作用:
把任何整数(可能为负或 ≥ 容量)映射到 [0, capacity-1] 的环形数组物理下标。
i 是未经修正的候选物理下标(可能越界)。
取余是为了实现环形环绕,不是简单的恒等变换。
